NVIDIA GB300 NVL72(2025.05.14)
2025.05.14
NVIDIA Grace CPU and Arm Architecture | NVIDIA
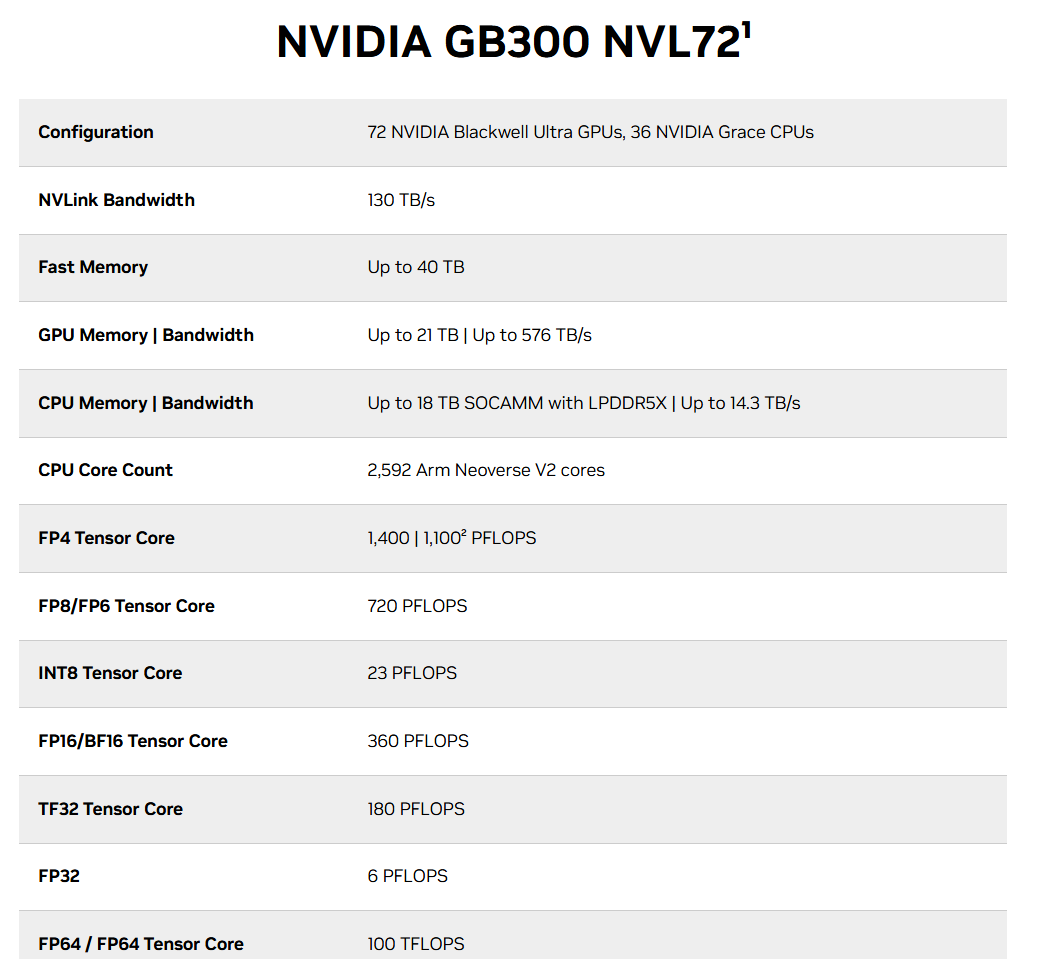
NVIDIA GB300 NVL72
NVIDIA GB300 NVL72 features 35X more AI inference performance than Hopper platforms, 40TB of fast memory, and networking platform integration with NVIDIA ConnectX®-8 SuperNICs using Quantum-X800 InfiniBand or Spectrum™-X Ethernet. NVIDIA Blackwell Ultra delivers breakthrough performance on the most complex workloads from agentic systems and reasoning to 30X faster real time video generation.
NVIDIA GB300 NVL72는 기존 Hopper 플랫폼 대비 AI 추론 성능이 35배 향상되었으며,
총 40TB의 초고속 메모리를 탑재하고,
NVIDIA ConnectX®-8 SuperNIC을 통해 Quantum-X800 InfiniBand 또는 Spectrum™-X Ethernet 네트워크 플랫폼과 통합됩니다.
NVIDIA Blackwell Ultra는
에이전트형 시스템(agentic systems)과 고차원적 추론(reasoning)부터
실시간 영상 생성(real-time video generation)을 30배 빠르게 수행하는 등
가장 복잡한 AI 워크로드에서도 획기적인 성능을 제공합니다.
개요
AI 추론 성능을 위한 설계
NVIDIA GB300 NVL72는 완전 수냉 방식의 랙 스케일 디자인을 채택하였으며,
72개의 NVIDIA Blackwell Ultra GPU와
36개의 Arm 기반 NVIDIA Grace™ CPU를 단일 플랫폼에 통합한 구조로,
test-time scaling inference에 최적화되어 있습니다.
이 플랫폼은 NVIDIA Quantum-X800 InfiniBand 또는 Spectrum™-X Ethernet 네트워크에
ConnectX®-8 SuperNIC을 조합하여 구성되며,
이를 기반으로 구축된 AI 팩토리는 기존 NVIDIA Hopper™ 플랫폼 대비
AI 추론 모델의 출력 성능을 50배 이상 향상시킬 수 있습니다.
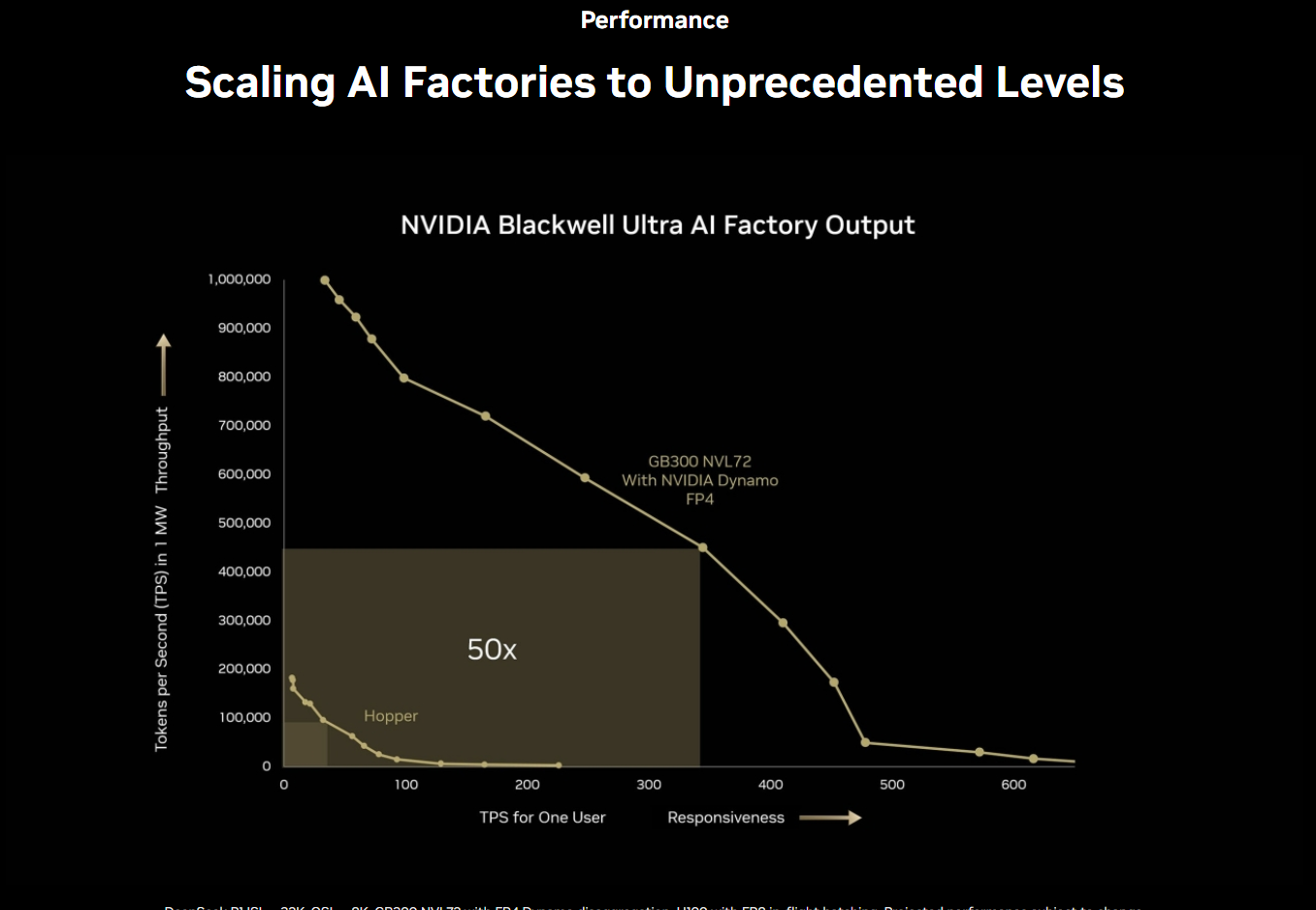
다음 그래프는 아래 내용을 담고 있다.
NVIDIA GB300 NVL72 플랫폼으로 차원이 다른 AI 추론 성능을 경험해보십시오.
기존 Hopper 플랫폼과 비교해, GB300 NVL72는 사용자 응답성(TPS per user)을 10배 향상시키고,
처리량(TPS per megawatt, 전력 대비 성능)은 5배 증가시킵니다.
이 두 가지 진보가 결합되어, AI 팩토리의 전체 성능은 무려 50배 향상됩니다.
※ 참고:
- **TPS (Transactions Per Second)**는 주로 LLM 추론 시 초당 생성 토큰 수 등을 의미하며,
- 이 문장은 GB300이 전력 효율성과 실사용자 응답성 모두에서 Hopper보다 획기적으로 개선되었음을 강조하고 있습니다.
"Scaling AI Factories to Unprecedented Levels"
AI 팩토리를 전례 없는 수준으로 확장하다


AI Reasoning Inference
Test-time scaling and AI reasoning increase the compute necessary to achieve quality of service and maximum throughput. NVIDIA Blackwell Ultra’s Tensor Cores are supercharged with 2x the attention-layer acceleration and 1.5x more AI compute floating-point operations per second (FLOPS) compared to NVIDIA Blackwell GPUs.
AI 추론 수행 (AI Reasoning Inference)
테스트 단계에서의 확장(test-time scaling)과 AI 추론(reasoning)은
서비스 품질(QoS)과 최대 처리량을 달성하기 위해 더 많은 연산 자원을 요구한다.
NVIDIA Blackwell Ultra의 텐서 코어(Tensor Cores)는
기존 Blackwell GPU 대비 2배 빠른 어텐션 레이어 가속,
1.5배 많은 AI 연산용 FLOPS(부동소수점 연산 성능)를 제공하도록 향상되었다.
288 GB of HBM3e
Larger memory capacity allows for larger batch sizing and maximum throughput performance.NVIDIA Blackwell Ultra GPU’s offer 1.5x larger HBM3e memory in combination with added AI compute, boosting AI reasoning throughput for the largest context lengths.
288GB의 HBM3E 메모리
더 큰 메모리 용량은 더 큰 배치 사이즈를 가능하게 하며, 최대 처리량 성능을 실현할 수 있다.
NVIDIA Blackwell Ultra GPU는 이전보다 1.5배 더 큰 HBM3E 메모리와 강화된 AI 연산 성능을 결합해,
가장 긴 컨텍스트 길이에서도 AI 추론 처리량을 크게 향상시킨다.
---------------------------------------
--------------------------
2025.03.18
NVIDIA Blackwell Ultra AI Factory Platform Paves Way for Age of AI Reasoning | NVIDIA Newsroom
NVIDIA Blackwell Ultra AI Factory Platform Paves Way for Age of AI Reasoning
Top Computer Makers, Cloud Service Providers and GPU Cloud Providers to Boost Training and Test-Time Scaling Inference, From Reasoning to Agentic and Physical AI
New Open-Source NVIDIA Dynamo Inference Software to Scale Up Reasoning AI Services With Leaps in Throughput, Faster Response Time and Reduced Total Cost of Ownership
NVIDIA Spectrum-X Enhanced 800G Ethernet Networking for AI Infrastructure Significantly Reduces Latency and Jitter
NVIDIA Blackwell Ultra AI 팩토리 플랫폼, AI 추론 시대의 서막을 열다
최상위 컴퓨터 제조사, 클라우드 서비스 제공업체, GPU 클라우드 기업들이
AI 훈련과 테스트 단계 추론(test-time scaling inference)을 가속하고,
추론형 AI, 에이전트형 AI, 물리적 AI까지 폭넓게 확장하고 있다.
NVIDIA의 새로운 오픈소스 추론 소프트웨어인 Dynamo는
AI 추론 서비스를 대규모로 확장할 수 있도록 설계되었으며,
이를 통해 처리량이 대폭 향상되고 응답 속도가 빨라지며 총소유비용(TCO)이 절감된다.
AI 인프라용 NVIDIA Spectrum-X 기반의 800G 고속 이더넷 네트워킹은
지연 시간과 지터를 획기적으로 줄여준다.
GTC — NVIDIA는 오늘 Blackwell AI 팩토리 플랫폼의 차세대 진화 버전인 Blackwell Ultra를 발표하며,
AI 추론 시대의 서막을 알렸다.
Blackwell Ultra는 훈련(training)과 테스트 단계 추론(test-time scaling inference)을 강화한다.
이는 추론 단계에서 더 많은 연산 자원을 투입함으로써 정확도를 높이는 방식으로,
전 세계 기업들이 AI 추론, 에이전트형 AI, 물리적 AI와 같은 애플리케이션을
보다 빠르게 구현할 수 있도록 돕는다.
1년 전 발표된 Blackwell 아키텍처를 기반으로 구축된 Blackwell Ultra에는
NVIDIA GB300 NVL72 랙 스케일 솔루션과 NVIDIA HGX B300 NVL16 시스템이 포함된다.
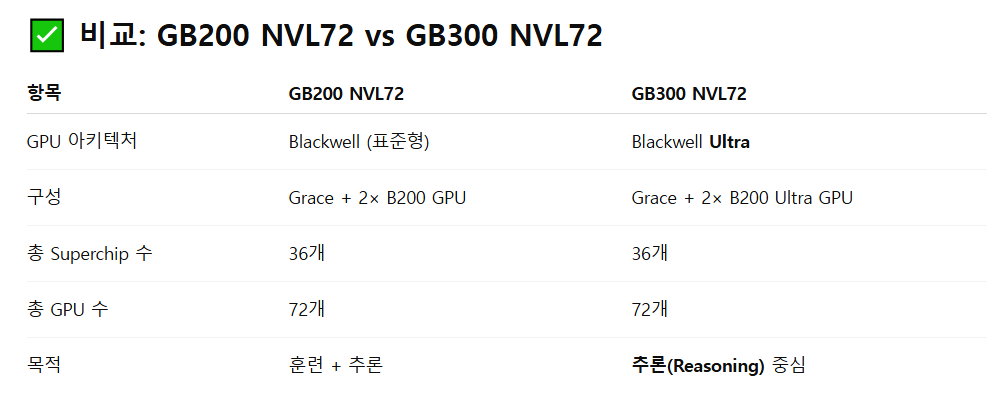
GB300 NVL72는 이전 세대인 GB200 NVL72보다 AI 성능이 1.5배 향상되었으며,
NVIDIA Hopper 기반 AI 팩토리와 비교해 Blackwell의 수익 기회를 최대 50배까지 확장할 수 있다.
"AI는 지금 거대한 도약을 이뤘습니다. 추론형 및 에이전트형 AI는 기존보다 수십 배 더 많은 연산 성능을 요구합니다."
NVIDIA 창립자 겸 CEO 젠슨 황은 이렇게 말했다.
"우리는 이 순간을 위해 Blackwell Ultra를 설계했습니다.
이 플랫폼은 사전 훈련, 사후 훈련, 추론형 AI 모두를 손쉽고 효율적으로 처리할 수 있는
다목적 통합 플랫폼입니다."
NVIDIA Blackwell Ultra Enables AI Reasoning
The NVIDIA GB300 NVL72 connects 72 Blackwell Ultra GPUs and 36 Arm
Neoverse-based NVIDIA Grace™ CPUs in a rack-scale design, acting as a single massive GPU built for test-time scaling.
With the NVIDIA GB300 NVL72, AI models can access the platform’s increased compute capacity to explore different solutions to problems and break down complex requests into multiple steps, resulting in higher-quality responses.
GB300 NVL72 is also expected to be available on NVIDIA DGX™ Cloud, an end-to-end, fully managed AI platform on leading clouds that optimizes performance with software, services and AI expertise for evolving workloads.
NVIDIA DGX SuperPOD™ with DGX GB300 systems uses the GB300 NVL72 rack design to provide customers with a turnkey AI factory.
The NVIDIA HGX B300 NVL16 features 11x faster inference on large language models, 7x more compute and 4x larger memory compared with the Hopper generation to deliver breakthrough performance for the most complex workloads, such as AI reasoning.
NVIDIA Blackwell Ultra, AI 추론을 가능하게 하다
NVIDIA GB300 NVL72는 72개의 Blackwell Ultra GPU와
36개의 Arm Neoverse 기반 NVIDIA Grace CPU를
랙 스케일 설계로 연결해, 단일 대형 GPU처럼 작동한다.
이 시스템은 test-time scaling에 최적화되어 있으며,
AI 모델은 이 플랫폼의 증가된 연산 성능을 활용해
다양한 해법을 시도하고, 복잡한 요청을 여러 단계로 나누어 처리함으로써
더 높은 품질의 응답을 생성할 수 있다.
GB300 NVL72는 NVIDIA DGX Cloud에서도 제공될 예정이다.
DGX Cloud는 주요 클라우드 환경에서 소프트웨어, 서비스, AI 전문성을 통합해 성능을 최적화하는
엔드 투 엔드 완전 관리형 AI 플랫폼이다.
DGX GB300 시스템을 기반으로 한 NVIDIA DGX SuperPOD는
GB300 NVL72 랙 설계를 사용해, 고객에게 즉시 사용 가능한 AI 팩토리를 제공한다.
한편, NVIDIA HGX B300 NVL16은 기존 Hopper 세대 대비
대형 언어 모델(LLM)에서 추론 속도는 11배, 연산 성능은 7배,
메모리는 4배 증가해, AI 추론과 같은 고복잡도 워크로드에서도 혁신적인 성능 향상을 제공한다.
In addition, the Blackwell Ultra platform is ideal for applications including:
- Agentic AI, which uses sophisticated reasoning and iterative planning to autonomously solve complex, multistep problems. AI agent systems go beyond instruction-following. They can reason, plan and take actions to achieve specific goals.
- Physical AI, enabling companies to generate synthetic, photorealistic videos in real time for the training of applications such as robots and autonomous vehicles at scale.
또한 Blackwell Ultra 플랫폼은 다음과 같은 분야의 활용에 이상적이다:
- 에이전트형 AI (Agentic AI):
고도화된 추론과 반복적 계획 수립을 통해 복잡하고 다단계적인 문제를 자율적으로 해결하는 AI.
이들은 단순한 명령 수행을 넘어서, 스스로 추론하고, 계획을 세우며, 목표 달성을 위해 실행할 수 있다. - 물리적 AI (Physical AI):
기업들이 로봇이나 자율주행차 학습용으로, 합성된 실사 수준의 영상을 실시간으로 생성할 수 있도록 해준다.
이를 통해 물리적 환경을 시뮬레이션하고, 대규모 AI 학습을 효율적으로 수행할 수 있다.
NVIDIA Scale-Out Infrastructure for Optimal Performance
Advanced scale-out networking is a critical component of AI infrastructure that can deliver top performance while reducing latency and jitter.
Blackwell Ultra systems seamlessly integrate with the NVIDIA Spectrum-X™ Ethernet and NVIDIA Quantum-X800 InfiniBand platforms, with 800 Gb/s of data throughput available for each GPU in the system, through an NVIDIA ConnectX®-8 SuperNIC.
This delivers best-in-class remote direct memory access capabilities to enable AI factories and cloud data centers to handle AI reasoning models without bottlenecks.
NVIDIA BlueField®-3 DPUs, also featured in Blackwell Ultra systems, enable multi-tenant networking, GPU compute elasticity, accelerated data access and real-time cybersecurity threat detection.
최적의 성능을 위한 NVIDIA의 스케일아웃 인프라
고성능 **스케일아웃 네트워킹(scale-out networking)**은
AI 인프라에서 지연(latency)과 지터(jitter)를 줄이면서 최상의 성능을 제공하는 핵심 요소다.
Blackwell Ultra 시스템은 NVIDIA Spectrum-X 이더넷과
NVIDIA Quantum-X800 InfiniBand 플랫폼과 매끄럽게 통합되며,
NVIDIA ConnectX-8 SuperNIC을 통해 GPU당 800Gb/s의 데이터 처리 속도를 제공한다.
이러한 구성은 업계 최고 수준의 원격 직접 메모리 접근(Remote Direct Memory Access, RDMA) 기능을 통해
AI 팩토리와 클라우드 데이터센터가 AI 추론 모델을 병목 없이 처리할 수 있도록 해준다.
또한, Blackwell Ultra 시스템에 포함된 NVIDIA BlueField-3 DPU는
멀티테넌트 네트워크 구성, GPU 연산 자원의 탄력적 배분, 데이터 접근 가속화,
그리고 실시간 사이버 보안 위협 감지를 가능하게 한다.
Global Technology Leaders Embrace Blackwell Ultra
Blackwell Ultra-based products are expected to be available from partners starting from the second half of 2025.
Cisco, Dell Technologies, Hewlett Packard Enterprise, Lenovo and Supermicro are expected to deliver a wide range of servers based on Blackwell Ultra products, in addition to Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron, Quanta Cloud Technology (QCT), Wistron and Wiwynn.
Cloud service providers Amazon Web Services, Google Cloud, Microsoft Azure and Oracle Cloud Infrastructure and GPU cloud providers CoreWeave, Crusoe, Lambda, Nebius, Nscale, Yotta and YTL will be among the first to offer Blackwell Ultra-powered instances.
글로벌 기술 선도 기업들, Blackwell Ultra 채택
Blackwell Ultra 기반 제품은 2025년 하반기부터 파트너사를 통해 출시될 예정이다.
Cisco, Dell Technologies, Hewlett Packard Enterprise, Lenovo, Supermicro를 비롯해,
Aivres, ASRock Rack, ASUS, Eviden, Foxconn, GIGABYTE, Inventec, Pegatron,
Quanta Cloud Technology(QCT), Wistron, Wiwynn 등은
Blackwell Ultra 기반 서버 제품을 다양하게 선보일 것으로 기대된다.
또한, Amazon Web Services, Google Cloud, Microsoft Azure, Oracle Cloud Infrastructure 등의
메이저 클라우드 서비스 제공업체와,
CoreWeave, Crusoe, Lambda, Nebius, Nscale, Yotta, YTL 등 GPU 클라우드 전문 업체들도
Blackwell Ultra 기반 인스턴스를 가장 먼저 도입하는 그룹이 될 전망이다.
NVIDIA Software Innovations Reduce AI Bottlenecks
The entire NVIDIA Blackwell product portfolio is supported by the full-stack NVIDIA AI platform.
The NVIDIA Dynamo open-source inference framework — also announced today — scales up reasoning AI services, delivering leaps in throughput while reducing response times and model serving costs by providing the most efficient solution for scaling test-time compute.
NVIDIA Dynamo is new AI inference-serving software designed to maximize token revenue generation for AI factories deploying reasoning AI models.
It orchestrates and accelerates inference communication across thousands of GPUs, and uses disaggregated serving to separate the processing and generation phases of large language models on different GPUs. This allows each phase to be optimized independently for its specific needs and ensures maximum GPU resource utilization.
Blackwell systems are ideal for running new NVIDIA Llama Nemotron Reason models and the NVIDIA AI-Q Blueprint, supported in the NVIDIA AI Enterprise software platform for production-grade AI.
NVIDIA AI Enterprise includes NVIDIA NIM™ microservices, as well as AI frameworks, libraries and tools that enterprises can deploy on NVIDIA-accelerated clouds, data centers and workstations.
The Blackwell platform builds on NVIDIA’s ecosystem of powerful development tools, NVIDIA CUDA-X™ libraries, over 6 million developers and 4,000+ applications scaling performance across thousands of GPUs.
Learn more by watching the NVIDIA GTC keynote and register for sessions from NVIDIA and industry leaders at the show, which runs through March 21.
NVIDIA, 소프트웨어 혁신으로 AI 병목 해소
NVIDIA Blackwell 제품군 전체는 NVIDIA의 풀스택 AI 플랫폼에 의해 지원된다.
이번에 함께 발표된 NVIDIA Dynamo 오픈소스 추론 프레임워크는
AI 추론 서비스의 확장성과 처리량을 크게 향상시키며,
응답 시간을 단축하고 모델 서빙 비용을 줄여,
test-time 연산을 효율적으로 확장하는 최적의 솔루션을 제공한다.
NVIDIA Dynamo는 추론형 AI 모델을 운영하는 AI 팩토리에서 토큰 기반 수익을 극대화하기 위해 설계된
새로운 AI 추론 서빙 소프트웨어다.
이 소프트웨어는 수천 개의 GPU에 걸쳐 추론 통신을 조율하고 가속화하며,
**대규모 언어 모델(LLM)의 처리 단계와 생성 단계를 분리(disaggregated serving)**하여
각 단계를 그에 맞게 최적화함으로써 GPU 자원을 최대한 활용할 수 있도록 한다.
Blackwell 시스템은 NVIDIA의 새로운 Llama Nemotron Reason 모델과
NVIDIA AI-Q Blueprint 실행에 이상적이며,
이는 기업용 AI 소프트웨어 플랫폼인 NVIDIA AI Enterprise에서 지원된다.
NVIDIA AI Enterprise에는 NVIDIA NIM 마이크로서비스,
AI 프레임워크, 라이브러리, 툴킷 등이 포함되어 있어,
기업이 NVIDIA 가속 클라우드, 데이터센터, 워크스테이션에서 손쉽게 AI를 배포할 수 있도록 해준다.
Blackwell 플랫폼은 NVIDIA CUDA-X 라이브러리, 600만 명 이상의 개발자,
4,000개 이상의 애플리케이션이 함께하는 NVIDIA의 강력한 개발 생태계를 기반으로 구축되었다.
더 자세한 내용은 NVIDIA GTC 기조연설을 시청하고,
3월 21일까지 진행되는 GTC에서 NVIDIA 및 업계 리더 세션에 등록하여 확인할 수 있다.