2026.01.23
요약: ICMS는 GPU를 쉬지 않게 만들기 위해, SSD를 ‘버퍼·백업·확장메모리’로 쓰게 만들었고,
그 결과 SSD 수요가 구조적으로 폭증한다.
DPU(Data Processing Unit)는 데이터센터에서 네트워크·보안·스토리지·인프라 관리 같은 작업을
CPU 대신 전담 처리하도록 설계된 전용 프로세서입니다.
쉽게 말해, CPU가 하던 ‘인프라 운영 업무’를 떼어내어 맡기는 관리·제어 전용 두뇌입니다.
엔비디아가 “AI 데이터센터 OS”처럼 밀고 있는 핵심 개념이 바로 ICMS입니다.
아주 쉽게 말하면,
ICMS = 초대형 AI 클러스터를 ‘하나의 컴퓨터처럼’ 관리·운영하는 시스템입니다.
1️⃣ ICMS란 무엇인가?
ICMS = Intelligent Compute Management System
엔비디아가 만든 AI 데이터센터 통합 운영 플랫폼이에요.
기존 데이터센터는
- 서버 따로
- GPU 따로
- 네트워크 따로
- 스토리지 따로
- 보안 따로 관리했는데,
ICMS는 이걸 전부 묶어서
👉 AI 팩토리 전체를 자동으로 운영하는 시스템으로 만든 겁니다.
2️⃣ 왜 ICMS가 등장했나? (배경)
요즘 AI 클러스터는 규모가 이렇죠:
- GPU: 수만~수십만 개
- HBM 메모리: 수백 TB
- 네트워크: 수백 Tbps
- NVLink 패브릭
- 수천 개 랙
이 정도 되면…
👉 사람이 수동으로 운영 불가능 ❌
예전 방식으로는:
- 장애 대응 느림
- 자원 배분 비효율
- GPU 놀림 발생
- 전력·냉각 낭비→ AI CAPEX 대비 효율이 급락
그래서 엔비디아가 “우리가 하드웨어 + 운영까지 다 책임지자”하고 만든 게 ICMS입니다.
3️⃣ ICMS의 핵심 구성 요소
ICMS는 혼자 있는 게 아니라, 여러 기술의 묶음입니다.
✅ ① BlueField DPU (핵심)
👉 ICMS의 “신경계”
- 네트워크 제어
- 보안 처리
- 스토리지 I/O
- 모니터링
전부 DPU에서 처리→ CPU/GPU 부담 제거.
✅ ② DOCA 플랫폼
👉 DPU용 운영체제 + 앱 플랫폼
ICMS 위에서 돌아가는 소프트웨어 기반입니다.
- 트래픽 제어
- 방화벽
- 암호화
- 스토리지 가속
✅ ③ NVIDIA Mission Control
👉 실제 운영 콘솔 (대시보드)
여기서:
- GPU 상태
- 온도
- 전력
- 네트워크 부하
- 장애 위치
전부 실시간 관리
✅ ④ Spectrum-X / NVLink Fabric
👉 네트워크 패브릭 통합 제어
- InfiniBand
- Ethernet
- NVLink
전부 ICMS에서 통합 관리
✅ ⑤ AI 자동화 엔진
👉 “운영도 AI로”
- 장애 예측
- 자동 복구
- 부하 재배치
- 에너지 최적화


6️⃣ 왜 투자·산업적으로 중요한가?
이 부분이 특히 중요합니다.
🔥 ① 엔비디아 락인(Lock-in) 완성
ICMS 구조:
GPU + DPU + 네트워크 + SW = 패키지
→ 다른 회사로 갈아타기 거의 불가능
👉 “AI판 Wintel” 구조 완성
🔥 ② 메모리·SSD 수요 폭증과 연결
ICMS 최적화 → GPU 가동률 ↑→ 학습·추론량 ↑
- HBM 수요 ↑↑↑
- DDR5 서버 RAM ↑
- NVMe SSD 캐시 ↑
→ 메모리 슈퍼사이클 가속.
🔥 ③ CSP의 운영비(OPEX) 절감
- 전력 ↓
- 장애 ↓
- 인력 ↓
→ AI ROI 개선
→ 투자 지속
→ 다시 GPU·HBM 주문 증가

8️⃣ 한 줄 요약
ICMS는 ‘GPU 공장’을 자동으로 굴리는 엔비디아의 AI 운영체제이며, 하드웨어 독점을 소프트웨어로 완성하는 무기다.
--------------------------
ICMS 때문에 SSD가 왜 폭증하는 이유는?
“왜 AI 시대에 HBM만큼이나 SSD가 중요해졌는가”**를 관통하는 핵심.
결론부터 말하면,
ICMS는 GPU를 최대한 쉬지 않게 만들고, 그 결과 ‘데이터 대기시간 제거용 SSD’가 폭증합니다.
입니다.
아래를 차근차근 연결해볼게요.
1️⃣ 기존 데이터센터 vs ICMS 데이터센터의 결정적 차이
🔹 기존 방식
예전 AI/서버 운영:
- 데이터: HDD / 느린 NAS
- GPU: 데이터 기다림 😴
- I/O 병목 많음
→ GPU 가동률 50~60%
👉 SSD 필요성 제한적
🔹 ICMS 방식
ICMS 목표:
GPU를 “절대 멈추지 않게” 만든다
그러려면?
👉 데이터 공급 속도를 GPU 속도에 맞춰야 함
그래서:
- HDD ❌
- 일반 SAN ❌
- → NVMe SSD 필수
2️⃣ ICMS 구조상 SSD가 필수가 되는 이유
✅ (1) ‘중앙 스토리지 → 분산 캐시’ 구조
ICMS는 구조가 이렇습니다:
[대형 스토리지]
↓
[로컬 NVMe 캐시]
↓
[GPU/HBM]
즉,
👉 모든 서버에 SSD 캐시를 깔아둠
이유:
중앙 스토리지는 아무리 빨라도 지연 있음
→ GPU 멈춤 = 손실 💸
그래서:
SSD를 “완충지대(Buffer)”로 씀
✅ (2) Checkpoint / Recovery 폭증
초대형 AI 학습 특징:
- 학습 수주~수개월
- 중간에 장애 나면 수천억 손실
그래서:
👉 수시로 상태 저장(CheckPoint)
이게 뭐냐면:
- GPU 메모리 상태
- 모델 파라미터
- 옵티마이저 값
전부 저장
→ 수십~수백 TB씩 쌓임
→ HDD로 불가능
→ SSD 필수
✅ (3) 데이터 파이프라인 자동화
ICMS는:
데이터 이동도 자동화
합니다.
예:
- Raw 데이터 수집
- 전처리
- 증강
- 샤딩
- 분배
이걸 실시간으로 돌림
중간 단계마다:
👉 임시 저장 공간 = SSD
✅ (4) DPU 중심 스토리지 가속 구조
ICMS + BlueField 구조:
GPU ↔ DPU ↔ NVMe SSD
CPU 거의 안 거침
→ Storage-over-Fabric
이 구조에서:
SSD = 네트워크 메모리처럼 사용됨
👉 “확장 메모리 역할”
3️⃣ 가장 중요한 포인트: ‘메모리 계층 확장’
AI 서버 메모리 구조를 보면:
HBM (1TB/s) ← 가장 비쌈
DDR5 (~200GB/s)
NVMe SSD (~10GB/s)
HDD (폐기수준)
ICMS는 이걸 하나의 계층으로 묶음.
즉:
SSD를 ‘느린 RAM’처럼 활용
합니다.
왜?
HBM은 너무 비쌈
DDR5도 한계
→ SSD로 확장
4️⃣ GPU 활용률 ↑ = SSD 수요 폭증 공식
이게 제일 중요합니다.
공식:
ICMS → GPU 활용률 ↑ → 데이터 소비 ↑ → SSD ↑↑↑
예전:
GPU 60% → 데이터 100 기준
ICMS 후:
GPU 95% → 데이터 160~180
👉 SSD가 못 버티면 병목
그래서:
GPU 1개당 SSD 용량이 계속 증가 중
세대GPU 1개당 SSD
| 2022 | 5~10TB |
| 2024 | 20TB |
| 2026E | 40~80TB |
(엔터프라이즈 기준)
5️⃣ 추론(Inference) 시대 → SSD 더 중요
학습보다 더 무서운 게 추론입니다.
이유:
LLM 추론 구조:
- 모델 일부 SSD에 저장
- 필요할 때 로딩
- 캐시 반복
특히:
MoE / RAG 구조
→ SSD 없으면 불가능
6️⃣ CSP 관점: SSD = ROI 장치
CSP 입장에서:
GPU 1대 = 수천만 원~억 단위
GPU 놀면:
→ 하루 수천만 손실
SSD 몇 백만 원 아끼다 GPU 놀리면?
→ 바보짓
그래서:
SSD는 무조건 넉넉히 깔음
7️⃣메모리 사이클 관점
이 구조 때문에 지금:
🔥 NAND 구조 변화
- 모바일/PC ↓
- 엔터프라이즈 ↑↑↑
- QLC ↑↑
- PCIe 5.0 필수
🔥 기업 수혜
영역 수혜
| NAND | 삼성·키옥시아·WD·마이크론 |
| SSD 컨트롤러 | Phison·Silicon Motion |
| 서버 SSD | 삼성·SK·Micron |
HBM 다음 사이클 = SSD 사이클입니다.
8️⃣ 한 줄 요약
ICMS는 GPU를 쉬지 않게 만들기 위해, SSD를 ‘버퍼·백업·확장메모리’로 쓰게 만들었고,
그 결과 SSD 수요가 구조적으로 폭증한다.
---------------------------
Inside the NVIDIA Rubin Platform: Six New Chips, One AI Supercomputer | NVIDIA Technical Blog
Inside the NVIDIA Rubin Platform: Six New Chips, One AI Supercomputer | NVIDIA Technical Blog
AI has entered an industrial phase. What began as systems performing discrete AI model training and human-facing inference has evolved into always-on AI factories that continuously convert power…
developer.nvidia.com
NVIDIA 루빈(Rubin) 플랫폼 내부: 6개의 신규 칩으로 구현된 하나의 AI 슈퍼컴퓨터
AI는 이제 본격적인 산업 단계에 진입했습니다.
과거에는 개별 AI 모델 학습이나 사람을 대상으로 한 추론을 수행하는 시스템이 중심이었지만, 이제는 전력·반도체·데이터를 지속적으로 지능으로 전환하는 항시 가동형 AI 공장(AI Factory) 으로 진화했습니다.
이러한 AI 공장은 비즈니스 전략 수립, 시장 분석, 심층 리서치 수행, 방대한 지식에 기반한 추론 등 다양한 고부가가치 응용을 뒷받침하고 있습니다.
이러한 기능을 대규모로 제공하기 위해, 차세대 AI 공장은 에이전트형 추론, 복잡한 워크플로우, 멀티모달 파이프라인에 필요한 장문 컨텍스트를 확보하기 위해 수십만 개의 입력 토큰을 처리해야 합니다. 동시에 전력, 신뢰성, 보안, 구축 속도, 비용 제약 속에서도 실시간 추론 성능을 안정적으로 유지해야 합니다.
NVIDIA 루빈 플랫폼은 바로 이러한 새로운 환경을 전제로 설계되었습니다.
루빈 플랫폼의 핵심 기반은 극단적인 공동 설계(Extreme Co-design) 입니다. GPU, CPU, 네트워크, 보안, 소프트웨어, 전력 공급, 냉각 시스템을 개별적으로 최적화하는 방식이 아니라, 하나의 통합 시스템으로 함께 설계했습니다. 이를 통해 루빈 플랫폼은 단일 GPU 서버가 아닌, 데이터센터 전체를 하나의 연산 단위로 취급합니다.
이러한 접근 방식은 대규모 환경에서 지능을 효율적이고 안전하며 예측 가능하게 생산할 수 있는 새로운 토대를 마련합니다. 또한 개별 부품의 벤치마크 성능이 아니라, 실제 운영 환경에서도 성능과 효율이 안정적으로 유지되도록 보장합니다.
이 기술 분석 글에서는 AI 공장이 왜 새로운 아키텍처를 필요로 하는지, NVIDIA 베라 루빈(Vera Rubin) NVL72가 랙 단위 아키텍처로 어떻게 작동하는지, 그리고 루빈 플랫폼의 반도체·소프트웨어·시스템이 대규모 환경에서 지속적인 성능과 토큰당 비용 절감을 어떻게 실현하는지를 설명합니다.
이 블로그는 다음과 같은 구성으로 이루어져 있습니다.
AI 공장이 왜 새로운 플랫폼을 필요로 하는가
추론 중심·상시 가동형 AI로의 전환과 함께, 대규모 운영을 규정하는 핵심 제약 조건인 전력, 신뢰성, 보안, 구축 속도의 변화에 대해 설명합니다.
NVIDIA 루빈 플랫폼 소개
랙 단위 플랫폼이라는 개념과, 지속적인 지능 생산을 가능하게 하는 핵심 기술적 돌파구를 다룹니다.
6개의 신규 칩, 하나의 AI 슈퍼컴퓨터
6칩 아키텍처 구조와 GPU·CPU·네트워크·인프라가 하나의 통합 시스템처럼 작동하는 방식을 설명합니다.
칩에서 시스템으로: NVIDIA 베라 루빈 슈퍼칩에서 DGX 슈퍼팟까지
루빈이 슈퍼칩에서 랙, 그리고 NVIDIA DGX SuperPOD 규모의 AI 공장 배포로 어떻게 확장되는지를 다룹니다.
소프트웨어와 개발자 경험
NVIDIA CUDA와 CUDA-X부터 학습·추론 프레임워크에 이르기까지, 랙 단위 시스템을 프로그래밍 가능하게 만드는 소프트웨어 스택을 설명합니다.
AI 공장 규모에서의 운영
운영, 신뢰성, 보안, 에너지 효율, 생태계 준비도를 포함한 대규모 생산 환경의 기반 요소를 다룹니다.
대규모 환경에서의 성능과 효율
학습에 필요한 GPU 수를 4분의 1로 줄이고, 추론 처리량을 10배 높이며, 토큰당 비용을 10분의 1로 낮추는 등, 루빈이 실제 환경에서 구현하는 성능 향상을 분석합니다.
왜 루빈이 AI 공장 플랫폼인가
극단적 공동 설계를 통해 실제 배포 환경에서 예측 가능한 성능, 경제성, 확장성을 어떻게 실현하는지를 설명합니다.
1. 왜 AI 공장은 새로운 플랫폼을 필요로 하는가
AI 공장은 기존 데이터센터와 근본적으로 다릅니다. 기존 데이터센터가 사람의 요청에 따라
간헐적으로 서비스를 제공하는 구조였다면, AI 공장은 항상 가동되면서 지능을 지속적으로 생산하는 시스템입니다.
이 환경에서는 개별 서버의 최대 연산 성능보다도, 추론 효율, 컨텍스트 처리 능력, 데이터 이동 효율이 전체 성능을 좌우합니다.
현대 AI 워크로드는 점점 더 긴 컨텍스트를 기반으로 다단계 추론을 수행하는 추론형·에이전트형 모델에 의존하고 있습니다.
이러한 워크로드는 플랫폼의 모든 계층에 동시에 부담을 줍니다.
실제 제공되는 연산 성능, GPU 간 통신 속도, 인터커넥트 지연 시간, 메모리 대역폭과 용량, 자원 활용 효율,
전력 공급 안정성까지 모두가 동시에 시험대에 오릅니다.
이러한 환경에서는 아주 작은 비효율도 수조 개 토큰 단위로 누적되면서, 전체 비용 구조와 처리량,
그리고 기업의 경쟁력을 크게 훼손할 수 있습니다.
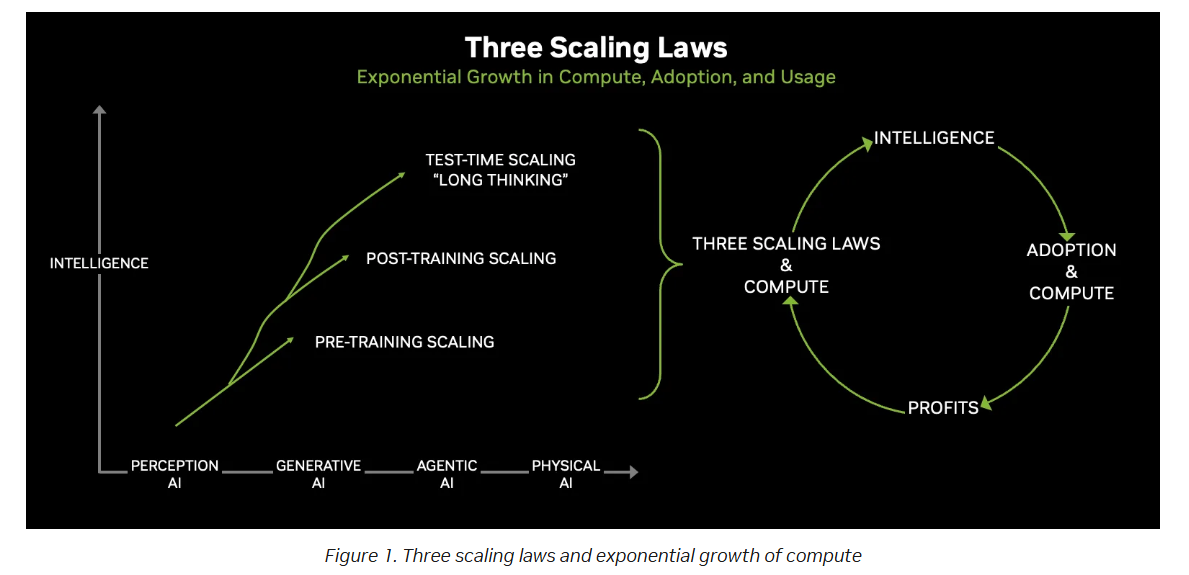
이러한 변화는 AI 발전을 이끄는 세 가지 스케일링 법칙으로 요약할 수 있습니다.
사전 학습 스케일링(Pre-training scaling)
모델이 기본적인 지식과 패턴을 학습하는 단계입니다.
사후 학습 스케일링(Post-training scaling)
미세조정과 강화학습을 통해 모델이 ‘사고하는 방식’을 학습하는 단계입니다.
테스트 단계 스케일링(Test-time scaling)
추론 과정에서 더 많은 토큰을 생성하며 논리적으로 사고하는 단계입니다.
'엔비디아-마이크로소프트-AMD-인텔' 카테고리의 다른 글
| NVIDIA BlueField Astra란 무엇인가?(2026.01.19) (1) | 2026.01.19 |
|---|---|
| 젠슨 황 “엔비디아, HBM4의 유일 사용자…H200 中 수출승인 막바지”(2026.01.07) (0) | 2026.01.07 |
| 2026CES 젠슨황 기조 연설(2026.01.06) (0) | 2026.01.06 |
| "엔비디아 사상 처음 있는 일"…젠슨 황 '29조' 쏟아부었다(2025.12.25) (0) | 2025.12.25 |
| "글로벌 반도체 매출 1000兆 시대"...삼성·SK하이닉스, 최대 수혜 본다(2025.12.15) (1) | 2025.12.15 |