2025.12.25
multimodal [mΛltimóudl] -->1.다모드의 2.다양식의 3.다양한
modality [moudǽləti] --1.양상 2.양태 3.법성
멀티모달(multimodal)은
서로 다른 종류의 데이터(모달리티)—예를 들면 텍스트, 이미지, 음성, 영상, 센서 데이터—를 함께 이해·처리·생성하는 기술
또는 AI 시스템을 말합니다.
멀티모달은 연산 구조를 변화시켜
- GPU + HBM 수요 폭증
- 영상·음성 처리 → 메모리 대역폭 의존 ↑
( AI 인프라·HBM 수요 확대와 직접 연결됨)
1️⃣ ‘모달리티’란?
모달리티는 정보가 표현되는 방식입니다.
- 텍스트: 문장, 숫자, 코드
- 이미지: 사진, 그림, 스캔 문서
- 음성: 사람 말소리, 환경음
- 영상: 연속 이미지 + 시간 정보
- 센서: 온도, 압력, LiDAR, 레이더 등
👉 멀티모달 = 두 가지 이상 모달리티를 동시에 다룸
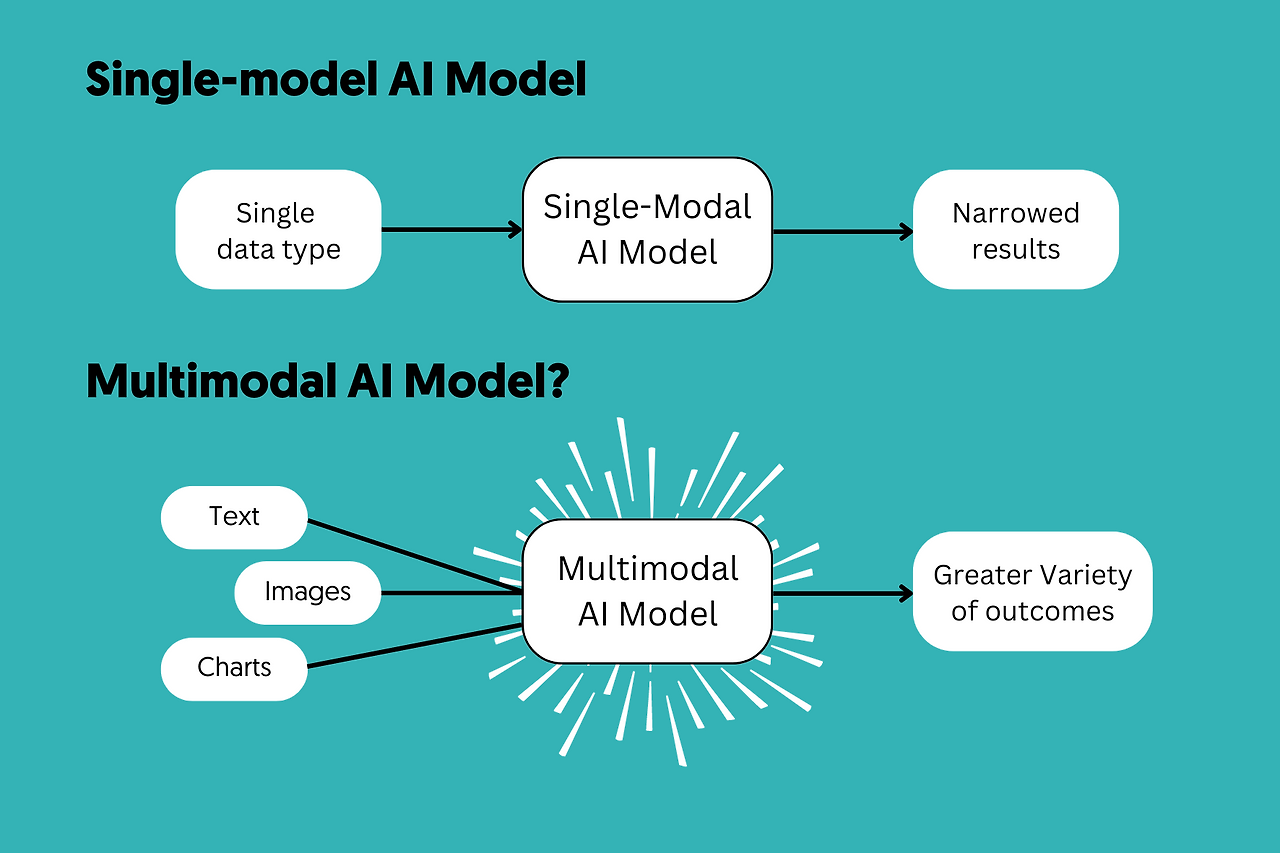
2️⃣ 싱글모달 vs 멀티모달
구분 예시 한계
| 싱글모달 | 텍스트만 이해하는 챗봇 | 이미지·소리 이해 불가 |
| 멀티모달 | 사진 보고 설명 + 질문 답변 | 현실 세계에 더 가까움 |
3️⃣ 멀티모달 AI는 무엇을 할 수 있나?
(1) 이해 (Understanding)
- 사진을 보고 무엇이 있는지 설명
- 그래프 이미지를 보고 수치 해석
- 영상 + 자막 + 음성을 함께 이해
(2) 변환 (Cross-modal)
- 이미지 → 텍스트 (OCR, 설명 생성)
- 음성 → 텍스트 (STT)
- 텍스트 → 이미지/영상 생성
(3) 추론 (Reasoning)
- “이 사진 속 사람이 왜 위험한 상황인가?”
- “이 그래프와 기사 내용을 종합하면 무슨 의미인가?”
(4) 행동 (Action)
- 로봇: 카메라 + 센서 + 언어 명령을 통합해 행동
- 자율주행: 영상·레이더·LiDAR·지도 결합
4️⃣ 직관적인 예시

- 📸 사진 찍고 “이게 뭐야?” → 설명 생성
- 🎤 말하면 자동으로 문서 작성
- ✏️ “노을 진 도시 그림 그려줘” → 이미지 생성
- 🤖 로봇이 보고(비전) 듣고(음성) 판단해 움직임
5️⃣ 왜 지금 멀티모달이 중요한가?
① 현실 세계는 원래 멀티모달
사람은 보고·듣고·읽고·촉각으로 동시에 판단함
② AI 활용 범위 폭발
- 자율주행
- 의료 영상 + 판독 리포트
- 스마트 팩토리
- AI 비서·로봇
③ 연산 구조 변화
- GPU + HBM 수요 폭증
- 영상·음성 처리 → 메모리 대역폭 의존 ↑
( AI 인프라·HBM 수요 확대와 직접 연결됨)
6️⃣ 멀티모달과 생성형 AI의 관계
- 생성형 AI: “만든다”
- 멀티모달: “여러 입력을 이해한다”
👉 최근 AI는 멀티모달 + 생성형이 결합됨
예: 이미지 보고 → 이해 → 텍스트/이미지/행동 생성
7️⃣ 한 줄 요약
멀티모달이란, AI가 텍스트·이미지·음성·영상 등 여러 감각 정보를 동시에 이해하고 연결해 추론·생성·행동하는 능력이다.
---------------------------
아래는 왜 멀티모달이 HBM/DRAM 수요를 ‘구조적으로’ 폭발시키는지를 연산 구조·메모리 접근 패턴·시스템 규모 관점에서
정리한 설명입니다.
한 줄 결론
멀티모달은 동시에 처리해야 할 데이터의 종류·양·연결성이 폭증해, 연산보다 ‘메모리 대역폭·용량’이 병목이 되며 HBM/DRAM 수요를 급증시킨다.
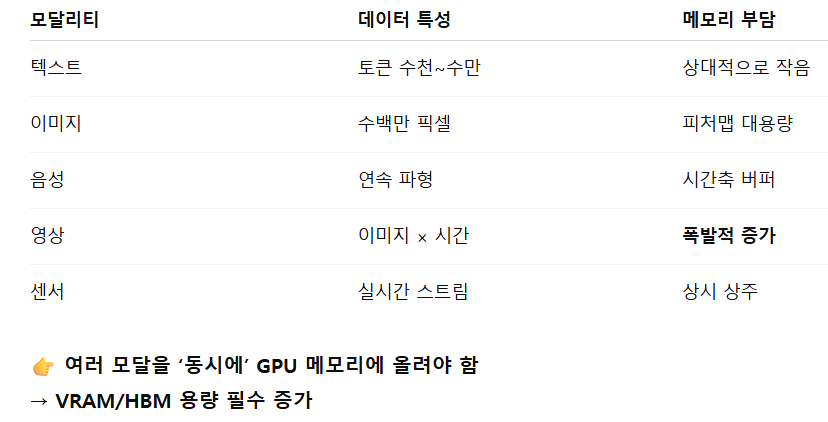
1️⃣ 입력 데이터 자체가 다차원·대용량
텍스트 대비 멀티모달 입력은 차원이 다릅니다.
2️⃣ 멀티 인코더 구조 = 메모리 상주 모델 수 증가
멀티모달 모델은 보통 모달별 인코더를 가집니다.

- 인코더마다 파라미터 + 중간 활성화(Activation) 상주
- 활성화는 추론 중 즉시 재사용 → 메모리 대역폭 민감
👉 “모델 하나”가 아니라 “모델 묶음”을 동시에 돌림
3️⃣ Fusion(결합) 단계가 메모리 지옥
멀티모달의 핵심은 Fusion입니다.
- 서로 다른 임베딩을 정렬·교차 어텐션
- 모든 모달 간 N×M 상호 참조
- 어텐션 = 대규모 메모리 읽기/쓰기
👉 연산량보다 메모리 이동량(Byte)이 급증
👉 HBM 없으면 GPU가 놀게 됨
4️⃣ 추론(inference)에서도 메모리 요구가 줄지 않는다
기존 가정: “메모리는 학습 때만 많이 든다” ❌
멀티모달에서는:
- 실시간 영상·음성 스트리밍
- 컨텍스트 길이 급증
- KV-cache (어텐션 캐시) 장기 유지
👉 추론 서버도 HBM/고대역 DRAM 필수
5️⃣ 배치 효율이 낮아진다 = 메모리 더 필요
텍스트 LLM:
- 배치 크게 묶기 쉬움
멀티모달:
- 영상 길이·해상도 제각각
- 센서 데이터 비동기
- 사용자 입력 다양
👉 배치 분할 → 메모리 낭비 증가
👉 같은 TPS를 내려면 GPU 수 + 메모리 용량 증가
6️⃣ 시스템 레벨에서 DRAM 수요도 동반 폭증
HBM만 늘어나는 게 아닙니다.

7️⃣ 왜 ‘HBM’이 특히 터지는가
멀티모달은 연산보다 대역폭이 문제입니다.
- 어텐션 = FLOPs보다 Bytes/s
- 영상·센서 = 스트리밍 접근
- Fusion = 랜덤 접근 + 반복 참조
👉 HBM의 초광대역(>5~8TB/s) 없으면 성능이 안 나옴
👉 “HBM이 곧 모델 크기·품질의 상한선”
8️⃣ 그래서 나타나는 시장 현상
- GPU 세대 교체마다 HBM 스택 수↑
- 추론 서버에도 HBM 탑재
- DDR5/DDR6 서버 메모리 상시 부족
- “메모리가 전략 자원”으로 격상
👉 HBM 구조적 쇼티지·DRAM 장기 타이트의 핵심 원인
핵심 요약 (3줄)
- 멀티모달은 동시 데이터 + 다중 인코더 + Fusion으로 메모리 상주량을 폭증시킨다
- 병목은 FLOPs가 아니라 메모리 대역폭과 용량이다
- 그래서 HBM이 AI 성능의 실질적 상한선이 된다
----------------
아래는“왜 학습이 아니라 추론(inference)이 중심이 되는 시대에도 메모리 슈퍼사이클이 끝나지 않는가”를
연산 구조·메모리 접근·서비스 형태 변화 관점에서 단계적으로 정리한 논리입니다.
한 줄 결론
추론 중심 시대의 병목은 연산(FLOPs)이 아니라 ‘메모리 대역폭·용량·상주성’이며, 멀티모달·장문 컨텍스트·실시간 서비스가 이를 구조적으로 고정시킨다.
1️⃣ 추론은 ‘가볍다’는 전제가 깨졌다
과거 추론:
- 짧은 입력
- 단일 모달
- 배치 처리 가능
지금의 추론:
- 멀티모달(영상·음성·텍스트 동시)
- 컨텍스트 수십만 토큰
- 실시간·개인화
- KV-cache 장기 유지
👉 연산량은 제한돼도 메모리는 줄지 않는다.
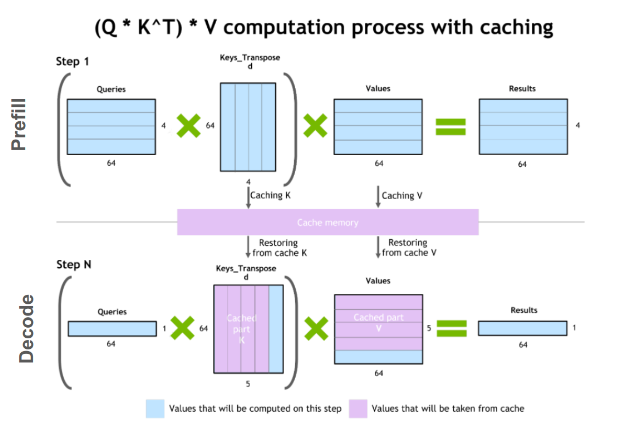
2️⃣ KV-cache가 메모리를 ‘상주 자원’으로 만든다
추론의 핵심 병목은 어텐션 캐시(KV-cache) 입니다.
- 토큰이 늘수록 캐시가 선형 증가
- 사용자 세션이 길수록 캐시 유지 시간 증가
- 멀티모달일수록 캐시 종류·차원 증가
👉 캐시는 “계산 후 버림”이 아니라
👉 GPU 메모리에 계속 머물러야 하는 자원
3️⃣ 멀티모달 추론 = 메모리 접근 지옥
멀티모달 추론에서는:
- 인코더 여러 개 상주
- Fusion에서 교차 어텐션 반복
- 스트리밍 입력(영상·음성) 지속 유입
👉 FLOPs 대비 메모리 읽기/쓰기 비율(Byte/FLOP) 급증
👉 HBM 대역폭이 성능을 결정
4️⃣ 배치 효율 붕괴 → 메모리 낭비 구조 고착
텍스트 LLM은 배치 묶기가 쉬웠지만:
- 영상 길이 제각각
- 음성 샘플링 다름
- 사용자별 컨텍스트 다름
👉 배치 축소
👉 같은 TPS를 내려면 GPU 수·메모리 용량 증가
5️⃣ ‘지연(latency)’이 최우선이 된다
추론 서비스는:
- 응답 지연 수 ms~수십 ms 요구
- 캐시 미스 허용 불가
- 메모리 압축·스왑 위험 회피
👉 HBM/DRAM을 넉넉히 깔아두는 설계가 정답
👉 메모리를 줄이면 비용↓가 아니라 서비스 품질 붕괴
6️⃣ 서버 메모리(DRAM)도 같이 늘어난다
GPU만의 문제가 아닙니다.
- 전처리·후처리
- 멀티 GPU 간 데이터 이동
- CXL 기반 확장 메모리
- 대형 컨텍스트 프리페치
👉 DDR5/DDR6 서버 메모리 상시 상주량 증가
👉 추론 중심일수록 CPU–GPU 메모리 파이프 두꺼워짐
7️⃣ 모델이 ‘작아져도’ 메모리는 줄지 않는다
경량화 트렌드가 있어도:
- 더 많은 동시 사용자
- 더 긴 컨텍스트
- 더 많은 모달
- 더 복잡한 에이전트 워크플로
👉 모델 파라미터 ↓
👉 메모리 트래픽·캐시·동시성 ↑
즉, 효율화는 수요를 제거하지 않고 확장시킴.
직관적 구조 그림

8️⃣ 그래서 메모리 슈퍼사이클이 끝나지 않는 이유 (정리)
- 추론이 메모리 상주 작업으로 변했다
- 멀티모달·장문 컨텍스트가 표준이 됐다
- 지연 민감 서비스는 메모리 축소를 허용하지 않는다
- 효율화는 사용량 확대로 이어진다
👉 결과적으로 HBM + DRAM은 구조적 부족 상태 유지
3줄 요약
- 추론 중심 시대의 병목은 연산이 아니라 메모리
- 멀티모달·KV-cache·실시간성이 메모리 상주 구조를 고정
- 그래서 메모리 슈퍼사이클은 끝나지 않고 형태만 진화한다
---------------------------
2025.12.25
엔비디아 오픈AI 아닙니다! 거의 모든 걸 가졌습니다 AI 최후 승자가 바뀔 겁니다 / 김정호 카이스트 교수 (1부)
'반도체-삼성전자-하이닉스-마이크론' 카테고리의 다른 글
| 중국 창신메모리 현황(2025.12.25) (1) | 2025.12.25 |
|---|---|
| 마이크론과 SK하이닉스 실적 비교(2025.12.25) (0) | 2025.12.25 |
| 메모리 슈퍼사이클, 마이크론과 경쟁사들에 본격적으로 힘이 실리다(2025.12.25) (0) | 2025.12.25 |
| LG전자-VS(Vehicle Solution,차량용 솔루션)부문(2025.12.24) (0) | 2025.12.25 |
| 메모리 부족(2025.12.22) (0) | 2025.12.22 |